최근 거대언어모델(LLM)은 자연어 처리뿐 아니라 그림과 영상을 포함한 멀티모달 학습 등 다양한 분야에서 핵심기능을 수행한다.
그러나 LLM은 수백억 파라미터의 고성능 GPU와 전용 네트워크 등 고비용 인프라를 필요로 하면서 거대기업 중심으로 운용되고 있다.
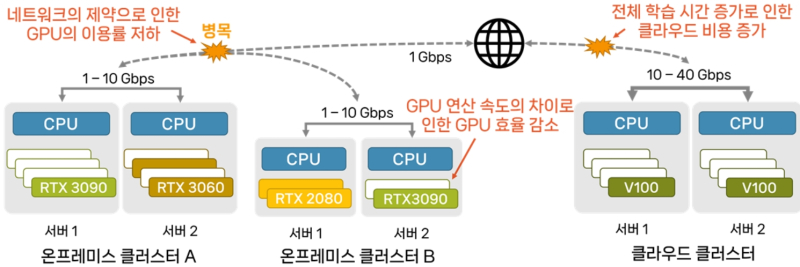
실제 현재 AI 모델을 학습하려면 개당 수천만 원의 엔비디아 H100과 같은 고성능 GPU를 여러 대 연결하기 위한 400Gbps급 고속 네트워크 인프라가 필요하다.
반면 대다수 연구자들은 소비자용 GPU를 활용하는 경우가 많아 LLM을 단순히 로딩하는 데에도 수십 대의 GPU가 필요하고, 네트워크 대역폭 및 메모리 제약으로 이용률이 떨어져 어려움을 겪고 있다.
이런 가운데 KAIST에서 고가의 데이터센터급 GPU나 고속 네트워크 없이도 인공지능(AI) 모델을 효율적으로 학습할 수 있는 기술을 개발해 AI 학습에 새로운 방향을 제시했다.
이를 활용하면 자원이 제한적인 학교나 기업 연구자들이 AI 연구를 보다 효과적으로 수행할 수 있을 것으로 기대된다.
보급형 GPU로 고성능 AI 학습 실현
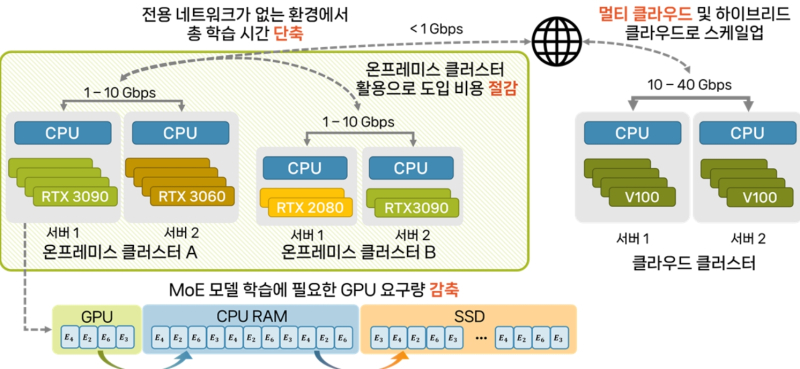
KAIST 전기및전자공학부 한동수 교수 연구팀이 일반용 GPU로 , 네트워크 대역폭이 제한된 분산 환경에서도 AI 모델학습을 수백 배 가속할 수 있는 기술을 개발했다.
연구팀은 분산학습 프레임워크 '스텔라트레인(StellaTrain)'를 개발, 고성능 H100의 1/20 수준으로 저렴한 GPU를 활용해 고속 전용 네트워크보다 대역폭이 수천 배 낮은 일반 인터넷 환경에서도 효율적인 분산 학습을 실현했다.
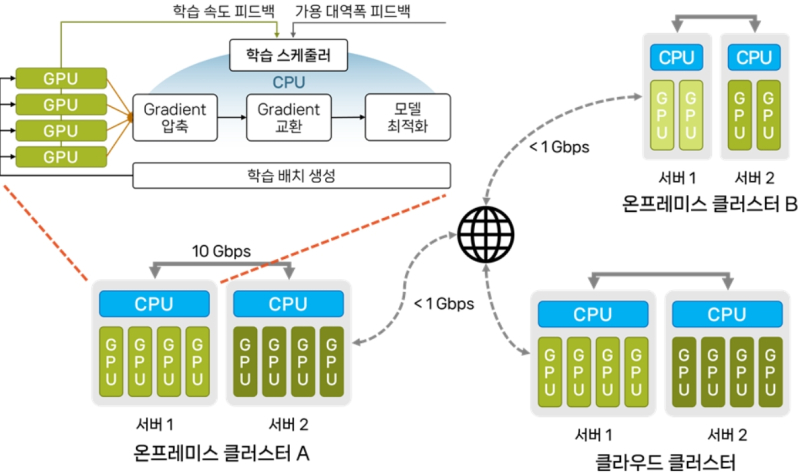
스텔라트레인은 범용 GPU 클러스터에서 모델학습을 가속하기 위해 여러 가속기법을 통합적으로 최적화하는 최초 프레임워크다.
이 기술은 메모리와 네트워크 속도가 제한적인 CPU와 GPU를 병렬로 활용해 학습속도를 높이고, 네트워크 속도에 맞춰 데이터를 효율적으로 압축 전송하는 알고리즘을 적용한 것이 특징이다.
연구팀은 기존 그래디언트 압축 및 파이프라이닝 기법 활용은 물론 학습가속을 위한 새로운 전략들을 도입, CPU에서 효율적으로 동작하는 희소 최적화 기술과 캐시 인식기반 그래디언트 압축기술을 새로 적용해 CPU 작업이 GPU 연산과 중첩되는 끊임없는 학습 파이프라인을 구현했다.
또 네트워크 상황에 따라 배치 크기와 압축률을 실시간으로 조절하는 동적 최적화 기술을 적용, 제한된 네트워크 환경에서도 높은 GPU 활용률을 달성했다.
이를 통해 고속 네트워크 없이도 여러 대의 저가 GPU를 이용해 빠른 학습이 가능하다.
특히 학습을 작업 단계별로 CPU와 GPU가 나눠 병렬 처리하는 새로운 파이프라인 도입으로 연산자원의 효율성을 극대화했다.
또 원거리 분산 환경에서도 GPU 연산효율을 높이기 위해 AI 모델별 GPU 활용률을 실시간으로 모니터링, 모델이 학습하는 샘플 개수를 동적으로 결정하고 변하는 네트워크 대역폭에 맞춰 GPU 간 데이터 전송을 효율화했다.
이를 적용한 결과 기존 데이터 병렬 학습보다 최대 104배 빠른 성능을 기록했다.
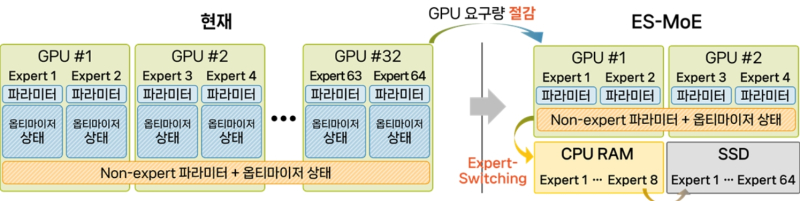
앞서 지난 7월 한 교수는 소수의 GPU로 메모리 한계를 극복하고 LLM을 학습하는 신기술을 발표했다.
이는 기존 32~64개 GPU가 필요한 150억 파라미터 규모 언어 모델을 단 4개의 GPU만으로도 학습할 수 있고, 이를 통해 학습에 필요한 최소 GPU 대수를 최고 1/16 수준으로 낮췄다.
한 교수는 “이번 연구로 데이터센터급 GPU와 고속 네트워크가 없는 환경에서도 효율적인 AI 모델학습이 가능해져 연구의 접근성을 크게 높일 것으로 기대된다”며 “이는 학계와 중소기업 등 자원이 제한된 환경에서 AI 연구개발을 가속시키고, 많은 연구자들이 LLM을 학습시킬 보편적 기회를 얻게돼 기술혁신을 가져올 것”이라고 설명했다.
한편, 이번 연구는 KAIST 임휘준 박사, 예준철 박사과정, UC 어바인 산기타 압두 조시 교수와 공동으로 진행됐고, 연구성과는 지난달 호주 시드니에서 열린 ‘ACM SIGCOMM 2024’에서 발표됐다.