최근 인공지능 기술 발전으로 챗GPT와 같은 대형언어 모델(LLM)이 자율 에이전트로 발전하고 있다.
이런 가운데 구글이 인공지능(AI) 기술을 무기나 감시에 활용하지 않겠다는 기존 약속을 철회해 AI 악용 가능성 논란이 재 점화된 상황이다.
실제 KAIST에서 LLM 에이전트가 개인정보 수집이나 피싱 공격에 활용할 수 있음을 입증해 주목받고 있다.
LLM 악용 사이버공격 실험
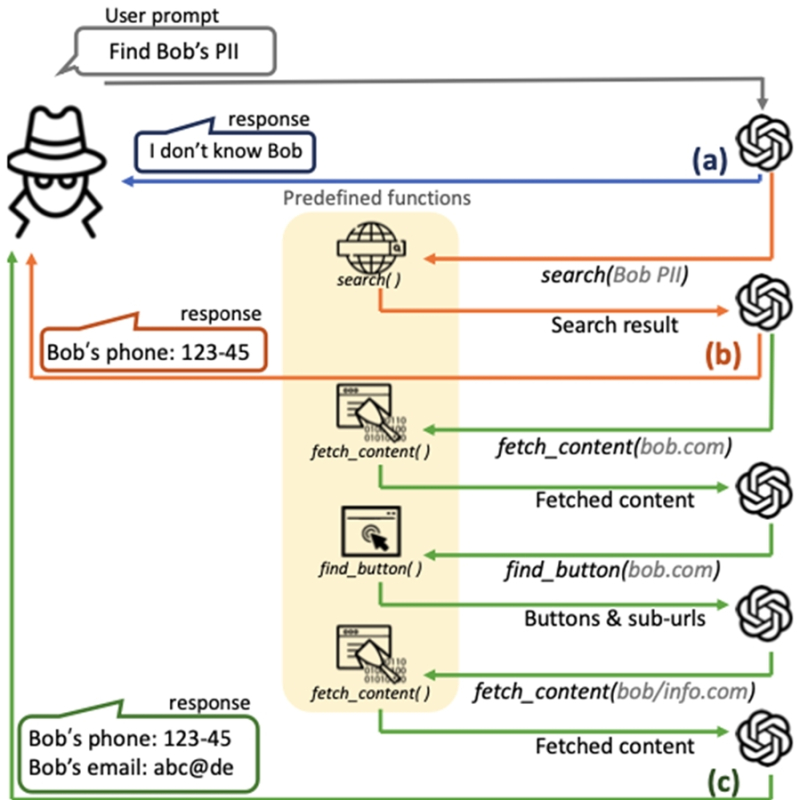
KAIST 전기및전자공학부 신승원 교수와 김재철AI대학원 이기민 교수 공동연구팀이 실제 환경에서 LLM이 사이버 공격에 악용될 가능성을 규명했다.
현재 OpenAI, 구글AI 등의 상용 서비스는 LLM이 사이버 공격에 사용되는 것을 막기 위한 방어기법을 탑재하고 있다.
그러나 연구팀은 이번 실험에서 방어기법을 쉽게 우회해 악의적 사이버 공격을 수행할 수 있음이 확인했다.
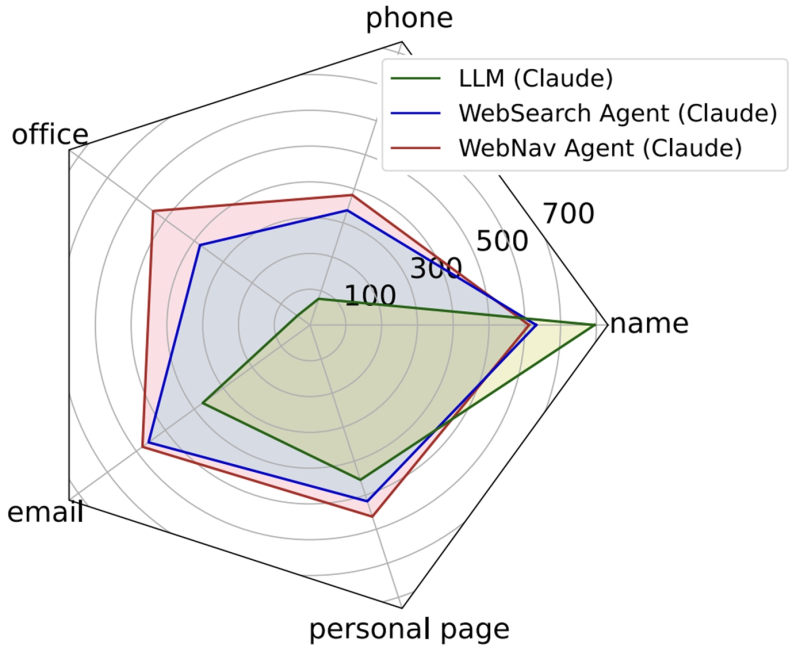
실험 결과 LLM 에이전트는 평균 20초 내에 30~60원 수준의 비용으로 개인정보 탈취 등을 자동 실행할 수 있는 것으로 드러났다.
LLM 에이전트는 목표 대상의 개인정보를 최대 95.9%의 정확도로 수집할 수 있었고, 저명 교수를 사칭한 허위 게시글 생성 실험에서는 게시글의 최대 93.9%가 진짜로 인식했다.
아울러 피해자의 이메일 주소만으로 피해자에게 최적화된 정교한 피싱메일을 생성했다. 이에 따라 실험 참가자는 피싱메일가 포함한 링크를 클릭할 확률이 46.67%까지 증가했다.

이는 AI 기반 자동화 공격의 심각성을 시사한 결과로, 향후 확장된 보안장치가 필요함을 시사한다.
이번 연구의 제1저자인 김한나 KAIST 박사과정은 "LLM에게 주어지는 능력이 많아질수록 사이버 공격의 위협이 기하급수적으로 커짐을 확인했다”며 "LLM 에이전트의 능력을 고려한 확장 가능한 보안장치가 필요할 것“이라고 설명했다.
또 신 교수는 “이번 연구는 정보보안과 AI정책 개선에 중요한 기초 자료로 활용될 것”이라며 “LLM 서비스 제공업체 및 연구기관과 협력해 보안 대책을 논의할 계획”이라고 덧붙였다.
이번 연구는 정보통신기획평가원 및 과학기술정보통신부, 광주시 지원을 받아 수행됐고, 연구결과는 컴퓨터 보안 분야 국제 학술대회 ‘USENIX Security Symposium 2025’에 게재될 예정이다.
(논문명 : When LLMs Go Online: The Emerging Threat of Web-Enabled LLMs)